-
Policies to Avoid Distance Computations - (1)CS/SimilaritySearch 2023. 5. 27. 09:34
이번 장에서는 '거리 계산'을 피하는 방법론에 대하여 다뤄보겠다.
개인적으로 이해하는데 꽤나 고생했던 부분이다.
거리를 측정한다는 것은 비싼 연산과정을 필요로 하기 때문에, 거리 측정에 대한 회수를 제한한다면
similarity queries를 처리하는데 필요한 속도를 향상시킬 수 있게 된다.
이러한 과정에 대한 전략을 'Pruning strategies(가지치기 전략)'이라 부르는데,
오늘은 이 가지치기 전략의 종류와 그 내용을 알아보자
1. Object-Pivot Constraint

다음과 같은 data structure이 있다고 하자.
Range query R(q,r)을 구해야하고, 현재 가장 왼쪽 leaf를 방문하고있다다 해보자.
평소대로라면 d(q,o4).d(q,o6),d(q,o10)를 모두 계산하여 그 값을 r과 비교하여야 한다.
하지만 data sturcture에 insertion(삽입) 당시, p2에서 o4,o6,o10의 거리가 이미 계산되어 저장되어있다면!?
-> Object - Pivot Constraint를 이용하여 Distance를 구하기 전에, 연산을 할 지 말 지 결정할 수 있다.
어떻게 결정을 할까?
다음 그림을 보자

o10을 예로 들어서 보자. o10이 주어진 궤도의 왼쪽에 위치한다면, d(q,o10)이 가장 짧을 것이다.(왼쪽 그림)
이는 d(p2, o10) - d(q,p2)의 값이다.
d(q,o10)이 가장 클 때는 d(p2,o10) + d(q,p2)인, 궤도에서 오른쪽에 위치할 때 일 것이다.(오른쪽 그림)
물론, o10의 위치가 지 맘대로 바뀔 수 있는 것은 아니다. 다만 우리가 p2와 각 object 사이의 거리를 미리 알고 있다면,
이를 이용하여 d(q,o10)의 최대값과 최소값이 얼만지 알 수 있다. 우리는 이 최소, 최대 값을 이용하는 것이다.
만약 d(q,o10)가 가질 수 있는 최대값이 R(q,r)의 r보다 작다고 해보자. 이 경우에는 굳이 d(q,o10)의 값을 따로 계산해 볼 필요 없이
o10이 조건에 부합한다는 것을 알 수 있다. (어떤 경우에도 반지름 r안에 들어간다)
이 조건이 d(q,o10)의 Upper bound이고, d(q,p2) + d(p2,o10)으로 표현할 수 있다.
반대의 경우도 생각해보자.
d(q,o10)이 가장 작은 경우인 |d(p2,o10) - d(q,p2)|를 생각해보자.
만약 이 가장 작은값도 구하고자 하는 쿼리의 반지름에 끼지 못한다면, 계산해볼 필요도 없이 o10이 찾고자 하는 값이 아님을 알 수 있다.
이 조건이 d(q,10)의 lower bound이고, |d(p2,o10) - d(q,p2)|로 표현할 수 있다.
이 둘을 합쳐보자.
- 거리 공간 M=(D, d)와 D에 속하는 object q,p,o가 주어졌을 때, 거리 함수 d(q,o)는 다음과 같이 constrained(제한)될 수 있다

즉, d(q,o)가 해당 범위 안에 있을 경우에만 정확한 distance의 계산이 요구된다.
d(q,o)의 값은 해당 범위 안에서 결정될 수 밖에 없다.
2. Range - Pivot Distance Constraint
위에서의 가정은, pivot과 object 사이의 거리가 data structure에 미리 저장되어 있을 경우에 대한 얘기었다.
하지만 모든 data structure가 피벗과 데이터 사이의 거리를 모두 저장해 놓는 것은 아니다.
이번 경우에는, pivot과 oi에 대한 각각의 거리가 저장되어 있는 경우가 아닌,
pivot과 해당 object들의 거리의 최소, 최대값이 저장되어 있는 경우라고 가정해보자.
예를 들면, pivot에 가장 가까운 object의 거리가 1이고, 가장 먼 object가 3의 거리에 있다 하면,
range[rl, rh] = [1,3] 으로 자료구조에 저장되어 있다고 가정하자는 것이다.

저번 경우에는 트리에 leaf노드에 진입한 후, 각 object들에 대해 계산 여부를 결정했다면,
이번 경우에는, 트리의 leaf 노드 자체에 진입할 지 말 지를 결정한다.
그럼 어떤 경우에 진입하고, 어떤 경우에 진입하지 않을까?

object - pivot constraint의 경우와 매커니즘은 유사하다.
d(q,oi)가 가질 수 있는 Lower bound는 rl - d(q,p2)이다.
가질 수 있는 가장 작은 값임에도 d(q,r), 즉 쿼리가 요구하는 범위 밖에 있으면,
해당 leaf에 존재하는 어떤 object도 쿼리를 만족시킬 수 없다.
반대로 upper bound인 rh + d(q,p2)값이 쿼리가 요구하는 범위 안에 있으면,
해당 leaf에 존재하는 모든 object는 일일이 계산해보지 않아도 쿼리의 요구사항에 부합한다.
이 경우에는 q의 위치에 대해 고려를 해 볼 필요가 있는데,

이렇게 세 가지의 가능성이 있다.
우리가 방금 본 경우는 2번째의 경우이다.
첫 번째 경우를 보면, d(q,p) - rh보다 작아질 때가 lower bound가 되고, upper bound는 같다.
셋 째 경우를 보면, 쿼리가 range안에 존재하기 때문에 lower bound는 존재하지 않는다. upper bound는 같다.
모든 내용을 종합하면, Range - pivot의 distance constraint는 다음과 같이 정해질 수 있다.

3. Pivot - Pivot Distance Constraint
지금까지는 leaf노드에 대해서만 constraint 규칙을 적용해보았다.
하지만 내부 노드에 대해서도 장난질을 해 볼 수 있다!

이번에는 루트 노드를 실행하고 난 후를 생각해보자.
우리는 어떤 서브트리가 무조건 방문되어야 하나 결정하기 위해서 range - pivot constraint를 적용할 수 있다.
- structure이 build 될 때 모든 data object들은 p1과 비교되었을 것이기 때문에, 우리는 범위를 알 수 있다.
우리가 p2 branch를 따라 내려왔다고 가정해보자.

d(p1,p2)는 알고 있고, 고정값이다. 따라서 d(q,p2)의 값은 d(q,p1)의 위치에 따라 최대와 최소가 달라진다.
- object - pivot constraint를 사용하면 -> d(q,p2)는 [rl', rh']범위 안에 존재한다.
- 이 때 rl' = | d(p1,q) - d(p1,p2) |, rh' = d(p1,p2) + d(p1,q)가 된다.
우리는 d(o,p2)의 범위 또한 알고있다-> p2의 서브트리 object들이 [rl, rh] 거리 사이에 존재한다 해보자.
혹시 여기까지 이해가 잘 안된다면 아래 두 가지를 기억하면서 다시 읽어보자.
1) 우리가 궁극적으로 구하고자 하는 것은 d(q,o)의 범위이다.
2) 이 d(q,o)의 범위를 d(q,p2)와 d(o,p2)를 이용하여 구할것이다.
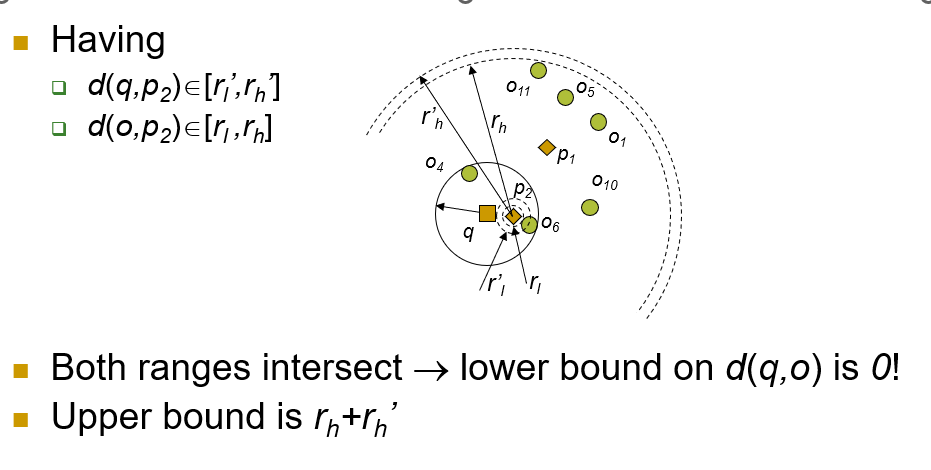
위그림을 이해해 보자.
- p2에서 q까지의 거리는 최소 rl', 최대 rh'이다
- p2에서 o까지의 거리는 최소 rl, 최대 rh이다.
Upper bound를 생각해보면, q와 o가 서로 반대에 위치한 rh + rh'가 된다는 사실은 자명하다.
Lower bound에 대해 생각해보자.
만약 [rl,rh] 과 [rl’,rh’] 범위에 겹치는 구간이 있다면, pivot p2로부터 q와 o가 같은 위치에 있을 수 있다는 얘기가 된다.
즉 -> lower bound는 0이다.
그럼 두 범위에 겹치는 구간이 존재하지 않는 상황에 대해 생각해보자.

위 그림은 [rl’,rh’]의 구간이 더 클 때이다.
이 경우 바깥 도넛의 안쪽인 r'l에서 안쪽 도넛의 바깥인 rh를 뺀 만큼이 lower bound이다.
즉 r'l - rh이다.
[rl’,rh’]의 구간이 더 작을때의 경우는
rl - r'h가 lower bound가 된다는 것을 쉽게 생각할 수 있을 것 이다.
결국, 우리는 다음과 같은 결론을 얻을 수 있다.
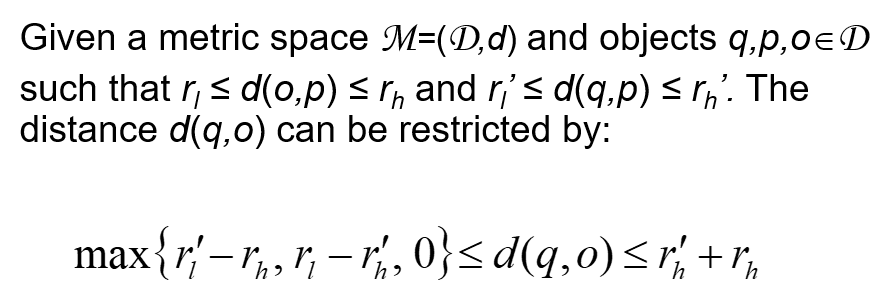
Pruning strategies(가지치기 전략)에는 double-pivot 전략과 pivot filtering전략이 더 있다.
이 두 전략은 다음 포스팅에서 설명하도록 하겠다.

'CS > SimilaritySearch' 카테고리의 다른 글
Principles of Approximate Similarity Search - (1) (0) 2023.05.27 Policies to Avoid Distance Computations - (2) (0) 2023.05.27 Principles of Similarity Query Execution (0) 2023.05.27 Basic partitioning principles (0) 2023.05.27 Similarity queries (0) 2023.05.27