-
Translating Melody to Chord: Structuredand Flexible Harmonization ofMelody With TransformerCS/논문 리뷰 2024. 4. 11. 03:36
장르를 반영한 멜로디에서 코드 생성 관련 연구를 하고있는데,
모델을 설계할때 참고하면 많은 도움이 될 만한 논문을 발견하여 리뷰하고자 한다.
제목 - Translating Melody to Chord: Structured and Flexible Harmonization of Melody With Transformer
저자 - Seungyeon Rhyu, Hyeonseok Choi
논문 게시일 - 2022.02
영문으로 작성된 논문이고, 번역 / 요약하여 정리해보았다.
https://ieeexplore.ieee.org/document/10096458
Music Mixing Style Transfer: A Contrastive Learning Approach to Disentangle Audio Effects
We propose an end-to-end music mixing style transfer system that converts the mixing style of an input multitrack to that of a reference song. This is achieved with an encoder pre-trained with a contrastive objective to extract only audio effects related i
ieeexplore.ieee.org
https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=9723052
IEEE Xplore Full-Text PDF:
ieeexplore.ieee.org
Abstract
최근 음악의 불균형한 코드 분포를 극복함으로써 음악 조화에 대한 딥러닝 접근법은 큰 성과를 이뤄냈다.
-> 불균형한 코드 분포? 어떻게 극복했을까.
하지만 이러한 접근법 중 대다수는 원본 멜로디 구조를 포착하고 적절한 리듬으로 구조화된 코드 시퀀스를 생성하려는 시도를 하지 않았다.
따라서 우리는 멜로디 음표(low-level)를 코드 시퀀스(high-level)로 직접 매핑하는 Transformer 기반의 아키택쳐를 이용했다.
특히, 멜로디의 이진 피아노 롤(piano roll)을 음표 기반(note-based) 표현으로 인코딩한다.
-> 이 방법을 통해서 '리듬으로 구조화된 코드 시퀀스를 생성'할 수 있을 것으로 보인다.
더 나아가 Transformer을 VAE 프레임워크로 확장하여 다양한 코드의 유연한 생성을 다룬다.
우리는 세 가지 모델을 제안한다.
1 - 멜로디를 코드로의 번역을 위한 standard transformer 기반 모델 - STHarm
2 - 전체 음악의 전역적인 표현을 학습하기 위한 변이 Transformer 기반 모델 - VTHarm
3 - 코드의 조작 가능한 생성을 위한 정규화된 변이 Transformer 기반 모델 -rVTHarm
-> 음악의 전역적인 표현 (global representation)이 뭘 의미하는걸까
Introduction
Automatic melody harmonization란 주어진 멜로디의 음표에 맞는 일관된 코드 순서를 찾는것으로,
-> 멜로디를 기반으로 코드를 생성하는, 내가 하고자 하는 주제와 동일하다. 이 논문에서는 Translation이나 Harmonization이라고 표현하는 듯 하다.
멜로디 하모니제이션 작업은 주어진 멜로디와 일관되게 상호작용하는 제한된 코드 진행 세트를 포착해야하므로,
음악의 장기적 종속성을 파악해야한다.
-> 이 부분이 이 논문의 차별점인 듯 하다
최근에는 양방향 장기 단기 메모리(BLSTM)를 사용한 딥 러닝 접근법이, 마디(bar)혹은 반 마디(half-bar) 단위의 멜로디와 코드에 대한 효과적인 비선형 순차 모델링으로 견고한 성능을 보였다.
또한, 이러한 연구들은 일반적인 음악 데이터에서 발생하는 불균형한 코드 분포를 성공적으로 극복했다.
그러나 이러한 LSTM 기반 연구들은 구체적인 코드 구조를 생성하는 데 2 가지 제한이 있다.
1 - 이러한 모델들은 순차적인 아키텍처에도 불구하고 원본 멜로디 구조를 인코딩할 수 없다.
멜로디의 음표들은 모델에 전달되기도 전에, 코드 지속 시간별 피치 클래스 히스토그램으로 집계된다.
-> 이 부분을 이해하는데 오래 걸렸다. 원본 멜로디의 구조를 인코딩할 수 없다는 것은, 결국 멜로디에 구조와는 상관없이 인코딩 과정에서 c 노트 몇개, d 노트 몇개(혹은 몇 time)으로 집계되기 때문에, 코드의 구조가 제대로 인코딩되지 않는다는 이야기다.
2 - 이러한 모델들은 코드 진행 패턴을 명시적으로 고려하지 않는다. 코드 라벨은 일정한 time-grid(ex: 한마디 또는 반마)에 대응된다. 그리드 기반의 코드 라벨을 순차적으로 모델링 하는 것은 생성된 출력의 모호한 패턴을 유발할 가능성이 높다.
따라서, 최근에 개발된 언어 모델인 Transformer를 구조화된 멜로디 조화에 활용하기로 시도한다.
Transformer는 두 시퀀셜 데이터 사이의 상호 및 내부 구조를 직접적으로 동적 길이로 인코딩한다.
따라서 Transformer를 사용하여 멜로디 조화를 두 가지 다른 언어 간의 번역으로 접근할 수 있다.
즉, 멜로디 음표와 코드 레이블은 의미적인 음악적 맥락을 공유하므로 서로 번역 가능하다.
-> 멜로디에서 코드 생성을, 멜로디를 번역해서 코드로 표현한다고 생각할 수 있다.
그러나 기존의 Transformer 기반 연구는 음악을 일련의 음악적 이벤트로 인코딩했다. 이벤트 기반 표현을 사용하는 것은 인간이 조화를 위해 렌더링 된 멜로디를 인식하는 방식과 다르다.
-> 이벤트 베이스라는 뜻은,
하지만, 그리드 기반의 멜로디 표현은 코드 레이블과 동기화된 멜로디 패턴을 모델링하기에 더 직관적일 수 있다. 따라서 여기에서는 각 프레임이 하나의 음표를 나타내는 더 직관적인 음표 기반 표현으로 멜로디를 변환한다. 이를 위해 바이너리 피아노 롤 표현을 음표 기반 임베딩으로 매핑하는 새로운 시간 대 음표 압축 방법을 사용다.
PROPOSED METHOD
구조화되고 유연한 멜로디 조화를 목표로 하는 Transformer를 기반으로 하는 세 가지 모델을 제안한다.첫 번째 모델은 표준 Transformer 모델을 사용하여 멜로디를 코드 순서로 번역한다.
두 번째 모델은 변이 Transformer를 사용하여 전체 음악의 전역적인 잠재적 표현을 학습한다.
마지막 모델은 변이 Transformer의 표현을 정규화하여 화음 속성을 제어한다.
이러한 모델들을 각각 STHarm, VTHarm 및 rVTHarm이라고 이름 지었다.
각 모델에서 Transformer 인코더는 주어진 멜로디를 받고, 디코더는 멜로디와 코드 간에 계산된 어텐션 가중치에 따라 코드 순서를 생성한다. 제안된 모델의 전반적인 구조는 그림 1에 설명되어 있다.
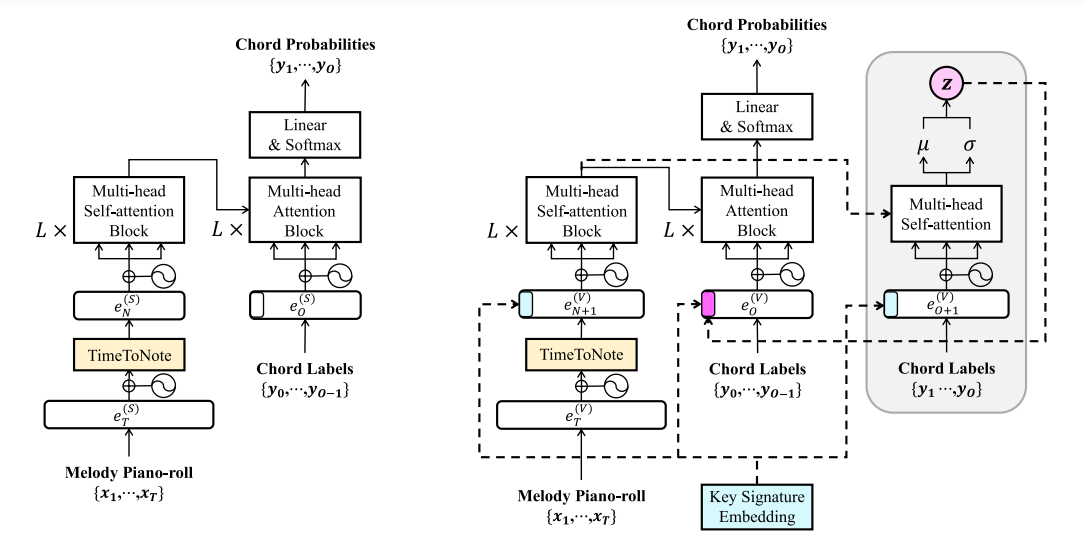
그림 1 x1:T ∈ {0, 1} T×|P|를, 주어진 멜로디의 one-hot 벡터 시퀀스라 하자. 여기서 T는 멜로디의 길이이고, |P|는 음의 수이며, t는 16분음표의 길이를 기준으로 한 시간 인덱스이다. 인코더는 입력 x1:T를 받아 (1)에서 표시된대로 음표별 멜로디 컨텍스트를 포착한다.

각 심볼에 대한 설명은 아래와 같이 표로 정리해 보았다!
eT time-level 임베딩 벡터 eN note-level 임베딩 벡터 S STHarm 모델 N 멜로디 음표 수 Embedding 임베딩 레이어 Self-AttBlocks L개의 멀티헤드 셀프 어텐션 블록 w 학습 가능한 가중치로 스케일된 사인 함수 위치 임베딩 TimeToNote 멜로디의 음표 패턴을 포착하기 위해 시간적 임베딩을 음표별 임베딩으로 변환하기 위해 제안된 새로운 방법 Time2Note 절차에서, 우리는 e(S)T에 조정된 위치 임베딩 wT를 추가한다.
그런 다음, 우리는 이를 피아노 롤과 일련의 음표 사이의 정렬 행렬 M ∈ {0, 1} T×N으로 average pooling을 통해 음표별 임베딩 e(S)N으로 변환한다.
여기서 M은 피아노 롤과 음표 사이의 정렬 경로를 나타낸다.
이 과정은 음표별 임베딩의 각 프레임이 원래 음표 지속 시간의 정보를 보존하도록 한다.
일단 오늘은 여기까지 살펴보도록 하고,
다음시간에는 모델의 세부 구조를 공부해보자!
'CS > 논문 리뷰' 카테고리의 다른 글
Harmonizers Transformer 'process_data.py' 코드 분석 (0) 2024.04.17 Harmonizers Transformer 논문 코드 재현 (0) 2024.04.14 Transformer-Based Seq2Seq Model for Chord Progression Generation (0) 2024.04.10