-
Principles of Approximate Similarity Search - (2)CS/SimilaritySearch 2023. 5. 28. 20:39

Measures of Performance
이번 포스팅에서는 근사 유사성 검사의 성능을 측정하는 방법에 대해 알아볼 것이다.
성능을 평가할 때 고려해야할 사항으로는,
- 효율성의 증가 정도
- 근사 결과의 정확도
위 두가지를 생각 할 수 있다.
일반적으로, 위의 두 사항은 서로 절충관계에 있다.
높은 효율성을 가진 알고리즘은 그만큼 정확도가 낮아진다.
Good approximate search 알고리즘이란, 높은 효울성을 가지면서 높은 정확도 또한 보장하는 알고리즘이다.
Measures of Performance: Improvement in Efficiency
성능을 측정하는 지표중 하나로, 효율성의 향상도가 있다.
효율성의 향상도는 -
쿼리의 정확한 실행 비용과 대략적인 실행 비용 사이의 비율로 표시된다.
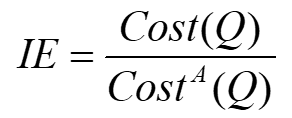
여기서 Cost(Q)는, 쿼리 실행을 위한 디스크 액세스 수 또는 거리 계산 수를 나타낸다.
즉, IE(Improvement in Efficiency)는 일반 유사도 검사의 코스트를 근사 유사도 검사의 코스트로 나눈 값이다.
단순하다!

만약 IE = 10이라 하면, 근사 유사도 검색의 실행 시간이 10배가 빠르다는 뜻이다.
Measures of Performance: Precision and Recall
성능을 측정하는 다른 지표로, 정확도와 리콜이 있다.
두 개념은 서로 비슷한 개념이라 생각하면 된다.
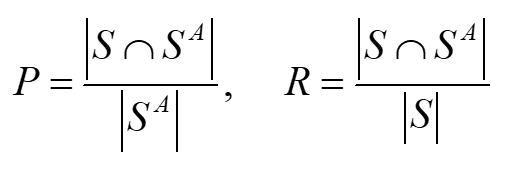
정확도(P)와 리콜(R)은 다음과 같이 표현되는데,
여기서 S는 정확한 검색 알고리즘을 이용했을 때 검색되는 object의 집합이고,
SA는 실제로 검색된 object의 집합이다.
다음 예를 한번 보면서 생각해보자.

10개의 nearest neighbor을 구하는 쿼리에 대하여,
정확한 알고리즘의 응답은 S{1,2,3,4,5,6,7,8,9,10}이다.
그리고 서로 다른 두 알고리즘이 각각 SA1과 SA2의 결과를 얻었다.
이 때, P를 구해보자. 서로 겹치는 부분을 구하는 분자는 9가 될 것이고, 분모는 10이다.
즉 A1알고리즘의 P = 0.9가 될 것이다.
마찬가지 방식으로 A1과 A2의 P, R을 모두 구해보면,
전부 0.9가 나온다.
여기서 P와 R의 중요한 단점이 나온다.
일반적으로 생각했을 때, SA2가 SA1보다 유용한 결과라고 볼 수 있을것이다.
집단 전체의 평균을 기준으로 생각하면, A2 object의 평균이 정확한 알고리즘의 평균값과 비슷하게 나온다.
하지만 P와 R은 원소의 개수를 기준으로 판단하기 때문에, 모든 원소들이 같은 중요도를 가질 때 유용한 알고리즘이다.
Relative Error on Distances
다음 지표로, ED를 살펴보자.
지표의 이름에서도 알 수 있듯이, 거리의 오차를 표현하는 지표이다.

ED는 다음과 같은 식을 통해서 구할 수 있다.
Approximate로 구한 qurey object와 object 사이의 거리 결과와 exact 방식으로 구한 결과를 비교하는 것이다.
OA와 ON은 각각 approximate와 actual 근접 이웃(NN)이다.
NN 쿼리가 아닌 K-NN쿼리에 적용할 수 있도록 일반화를 하게되면,
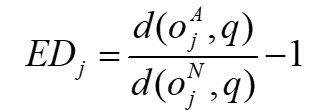
위와 같은 수식으로 표현할 수 있다.
하지만 ED 지표는 거리의 분포도를 계산에 반영하지 않는다는 단점이 있다.
다음 예시에 대해 생각해보자.
Example 1 - ON과 OA의 거리가 멀 때

다음과 같이 원래 정답인 ON을 놓치고 OA를 선택했다고 가정해보자.
K-NN 쿼리에서 다음과 같이 거리가 먼 object를 하나 놓치게 되면,
딱 1개의 object만 놓치게 되어도 ED의 값은 커지게 된다.
Example 2 - 거의 모든 object들이 쿼리 object로 부터 비슷한 거리를 갖고있을 때
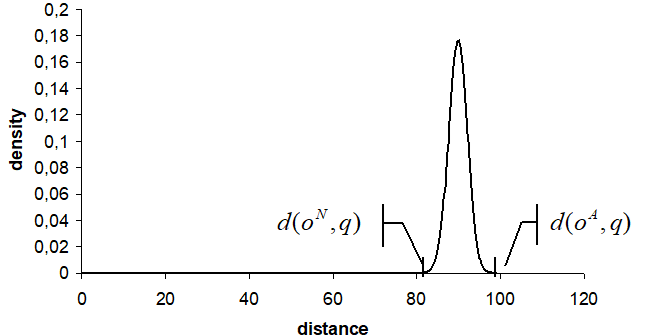
가장 가까운 object가 아닌 가장 먼 object를 선택하게 되어도 ED의 값은 작게 나온다.
중간에 매우 많은 object들을 놓쳤음에도, 그래도 ED의 값은 작기 때문에 좋은 알고리즘으로 착각할 수 있는 것이다.
Error on Position
또 다른 지표로 Error on Position(위치의 오차)가 있다.
Sperman Footrule Distance(스페르만 풋룰 거리)를 사용하여 구하는 방법인데,
SFD의 공식은 아래와 같다.

|X|는 데이터셋의 크기(원소의 개수)를 의미하고,
Si(o)는 정렬된 list Si에서의 object o의 위치를 의미한다.
부분 리스트에 대해서는 Induced Footrule Distance를 사용하며 IFD의 공식은,

다음과 같다.
OX는 q에 대해 정렬된 전체 데이터셋을 포함하는 리스트이며,
SA는 q에 대해 정렬된 approximate 알고리즘의 결과이다.
위 공식을 이용하여 EP를 계산하는 방법은,

위와 같다.
이렇게 공식만 들어서는 도무지 이해가 잘 되지 않는다.
예시를 보며 이해해보도록 하자.
크기가 10000인 데이터셋 X가 있다고 해보자.
이 데이터셋에 대하여 10-NN을 구하는 쿼리를 실행한다.

(위에서 다뤘던 예시와 같은 예시이다)
S는 정확한 유사도 알고리즘,
SA1과 SA2는 근사 유사도 알고리즘을 통해 구한 result이다.
이제 EP를 구해보자.
SA1의 경우, EP = 10 / (10 * 10000) = 0.0001이다.
(공식의 분모는 1을 10번 더해나온 10이고, 분자는 데이터셋의 크기에 result set의 크기를 곱한 10 * 10000이다)
SA2의 경우, EP = 1 / (10 × 10,000) = 0.00001이다.
즉, P R 지표와는 다르게 SA1이 더 좋은 알고리즘이라고 말해준다.
'CS > SimilaritySearch' 카테고리의 다른 글
Advanced Issues - (2) (0) 2023.05.29 Advanced Issues - (1) (0) 2023.05.29 Principles of Approximate Similarity Search - (1) (0) 2023.05.27 Policies to Avoid Distance Computations - (2) (0) 2023.05.27 Policies to Avoid Distance Computations - (1) (0) 2023.05.27