-
Advanced Issues - (1)CS/SimilaritySearch 2023. 5. 29. 04:05
데이터 셋이 가지는 통계적인 특징들은 데이터베이스의 성능 최적화의 기초가 된다.
이러한 통계적 특징들을 이용하여 Cost models를 만든다던가, Access structure tuning등을 할 수 있다.
이러한 통계적 정보들로는, 데이터베이스의 레코드에 대한 빈도 값 히스토그램이나 데이터의 분산 등이 있을 수 있다.
하지만,,
이러한 통계적 특성들을 일반적인 metric space에서는 사용하지 못한다.
Metric space의 특성은 이 카테고리의 첫 번째 글에 설명해두었다.
Metric space에서는 오로지 distance(거리)라는 변수에 의존해야하며,좌표계를 사용 할 수 없다.
하지만 통계를 사용하면 얻을 수 있는 이점들은 뽑아먹고 싶다.그래서 오늘은 metric space를 이용한 유사도 검색에서 사용할 수 있는 통계적 기술들에 대해 다뤄보겠다.
아래 세 가지에 대해 다뤄볼 것이다.
- Distance density and distance distribution
- Homogeneity of viewpoints
- Proximity of ball regions
1. Distance density and distance distribution
일단 Data density와 Distance density의 차이점에 대해서부터 알아보자.
Data Density vs. Distance Density

간단하게 말해서 Data Density는 벡터 공간, Distance density는 Metric 공간에서 사용할 수 있다는 얘기이다.
즉 우리는 Distance Density를 필요로 한다.
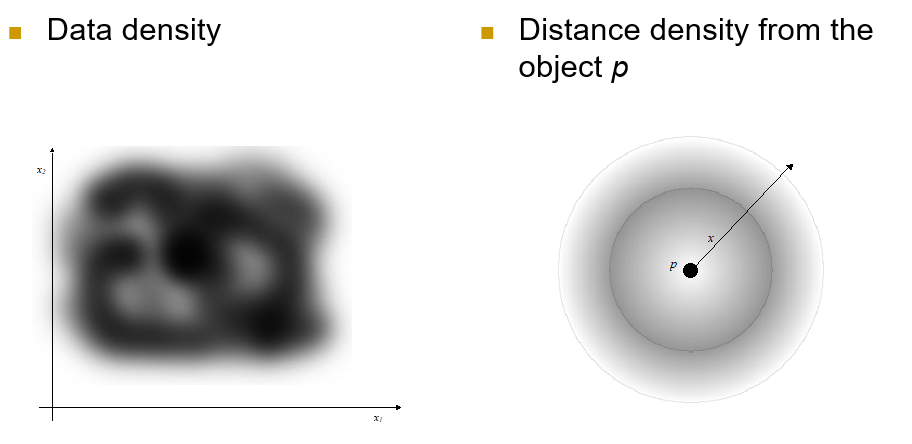
두 Density를 그래프로 표현하면 다음과 같다.
좀 더 직관적으로 들어온다.

이제 Distance distribution에 대해 알아보자.
object p에대한 distance distribution은 다음과 같이 표현할 수 있다.
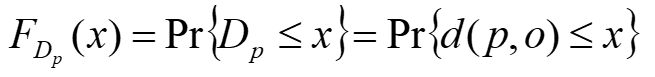
여기서 Dp는 distance d(p,o)에 상응하는 랜덤 변수이고, o는 metric space의 랜덤 object이다.
object p로부터의 거리 밀도(distance density)는 분포의 도함수로 얻을 수 있다.
다음은 전체 거리 분포(overall distance distribution)이다.
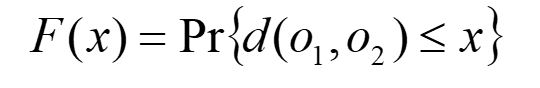
전체 거리 분포는(일반적으로) 개체 간의 거리 확률을 나타낸다.
위 수식에서 o1과 o2는 metric space에 존재하는 랜덤 object를 나타낸다.
2. Homogeneity of viewpoints
직역하면 관점의 동차성이라고 해석할 수 있겠다.
어떤 object p에서 다른 object까지의 거리 분산은, 그 viewpoint의 위치에 대해서 다 다르다.
->서로 다른 object간의 거리는 다르게 분포해있다.
그리고 전체 거리 분포는, 집합 전체의 거리분포를 특징적으로 보여주는 것이기 때문에, 개별적인 viewpoint와는 또 다르다.
하지만!! 만약 데이터 집합이 확률적으로 균질한 경우라면 (dataset is probabilistically homogeneous),
전체 거리 분포를 어떤 viewpoint에도 적용할 수 있게된다.

다음은 HV(M)을 구하는 공식이다.
여기서 나온 HV(M)의 값이 1과 유사하다면, 전체 거리 분포를 어느 viewpoint에도 적용할 수 있게 된다.
3. Proximity of Ball Regions
두 영역의 근접성(Proximity of Ball Regions)은 중첩에 포함된 object의 수를 추정하는 측도이다.
다음 같은 상황에 주로 사용한다.
- 파티셔닝을 위한 영역 분할 : 한 영역을 분할 하고 나서, 새로운 영역은 가능한 적은 개체를 공유해야 한다.
- 디스크 할당 : 여러 디스크에 데이터를 분산하여 성능을 향상시킨다.
- 근사 검색 : 교차로에 object가 있을 가능성이 높은 경우 영역에 접근하는 방식으로 relaxed branching strategy에 적용할 수 있다.
첫 번째로, 파티셔닝을 위한 영역 분할을 살펴보자.
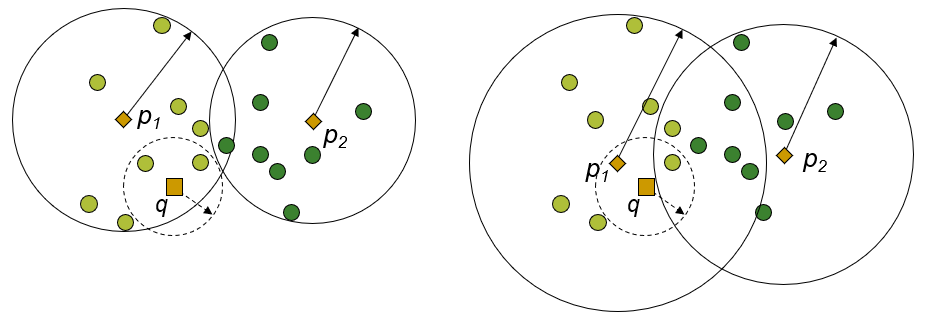
오버랩 되는 부분을 최소화 하기 위해서, 데이터를 파티셔닝 하는 과정이 필요할 수 있다.
좋은 파티셔닝을 사용하지 않으면(데이터의 중첩이 많으면), 같은 데이터를 두 번 접근할 소요가 생기기 때문에,
좋은 파티셔닝을 하기 위한 영역 분할 방법에서 Proximity of Ball Regions을 사용한다.
(이러한 이유로 왼 쪽의 파티셔닝이 더 좋은 파티션이라 할 수 있다.)
두 번째로, 디스크 할당에 대해 살펴보자.
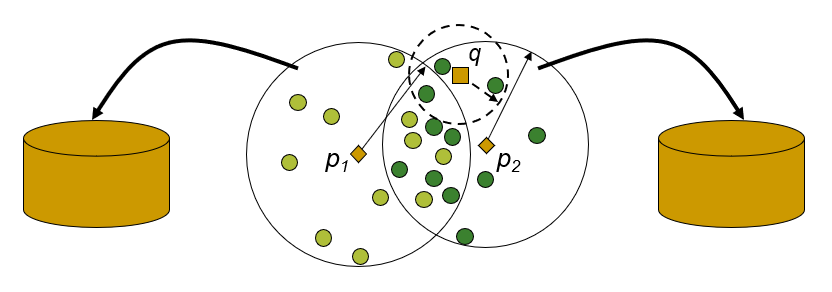
위와 같이, 많은 데이터들을 공유하고 있는 영역은 서로 다른 디스크에 할당되는것이 좋을 것이다.
그렇지 않으면, 같은 쿼리에 의해 함께 access될 확률이 높기 때문이다.
따라서 효율적인 디스크 할당을 위하여 Proximity of Ball Regions 개념을 사용할 수 있다.
세 번째로, 근사 검색에 대하여 살펴보자.
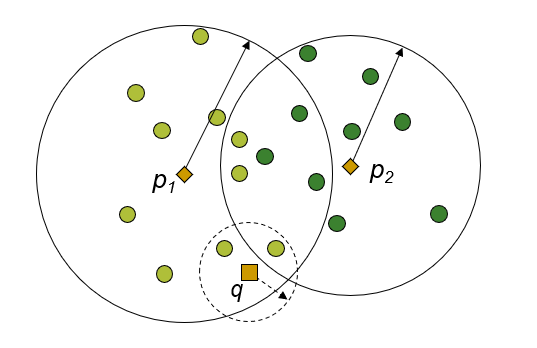
이전 챕터에서 근사검색에 대하여 다뤘었다.
근사 검색의 두 가지 종류인, '일찍 끝내기'와 '가지치기' 방식 중에 두 번째 방법에 적용할 수 있다.
만약 중첩부분에 찾고자 하는 데이터가 있을 확률이 높다면 접근하고, 그렇지 않으면 접근하지 않도록 결정할 수 있는것이다.
다음 포스팅에서는, Proximity of Metric Ball Regions에 대하여 조금 더 자세히 다뤄보겠다.
'CS > SimilaritySearch' 카테고리의 다른 글
Tree Quality Measures (0) 2023.06.01 Advanced Issues - (2) (0) 2023.05.29 Principles of Approximate Similarity Search - (2) (0) 2023.05.28 Principles of Approximate Similarity Search - (1) (0) 2023.05.27 Policies to Avoid Distance Computations - (2) (0) 2023.05.27